Research
深度学习技术在当前AI安全领域取得了显著的成功。其主要应用领域涵盖深伪取证、活体检测和模型水印等任务。深伪取证专注于对数字内容进行取证,旨在检测和识别深度伪造内容。借助深度神经网络,可以高效地进行深伪取证工作。活体检测的主要目标是辨别真实的活体目标。深度神经网络能够准确地捕捉真实活体目标的特征和行为,为活体检测提供可靠的技术支持。模型水印是在AI系统中嵌入隐藏信息,以验证系统的真实性和可靠性。深度学习技术在解决模型水印任务方面表现出色,能够在保持模型性能的同时,训练带有模型水印的模型。通过正确的水印标签,即可完成模型的验证。



来源取证(Source Attribution)是计算机科学和法律领域中一项重要的研究方向,其旨在通过结合技术手段和法律手段,明确数字证据的来源和可信度,从而应对计算机犯罪、网络欺诈、知识产权侵犯等问题。该领域的研究具有重要的实际应用价值。在数字时代,各类数字证据被广泛应用于法律案件、安全调查、商业纠纷等多个领域。通过来源取证的研究,我们能够更加有效地确认数字证据的真实性和可信度,为解决涉及数字证据的各种问题提供有力的支持。这对于保障司法公正、确保安全调查的准确性,以及防范商业纠纷的发生都具有重要意义。同时,来源取证的研究也有助于推动相关法律法规和标准的制定和完善,提高数字证据在法律程序中的法律效力和可信度。
图像篡改检测是指利用计算机技术和图像处理算法,对图像进行自动分析,以识别和检测图像是否被篡改或修改过的过程。图像篡改可能包括图像拼接、复制粘贴、对象移除、色彩篡改等多种手段。图像篡改检测技术在许多领域都有应用,如数字取证、安全监控、社交媒体内容真实性验证等。图像篡改检测的关键在于提取图像的特征并比较它们之间的差异。这些特征可能包括像素值、纹理、颜色、形状等。通过比较原始图像和疑似篡改图像之间的特征差异,可以检测出图像是否被篡改。此外,基于深度学习的算法,研究人员可以通过训练模型来识别和检测图像中的篡改痕迹。

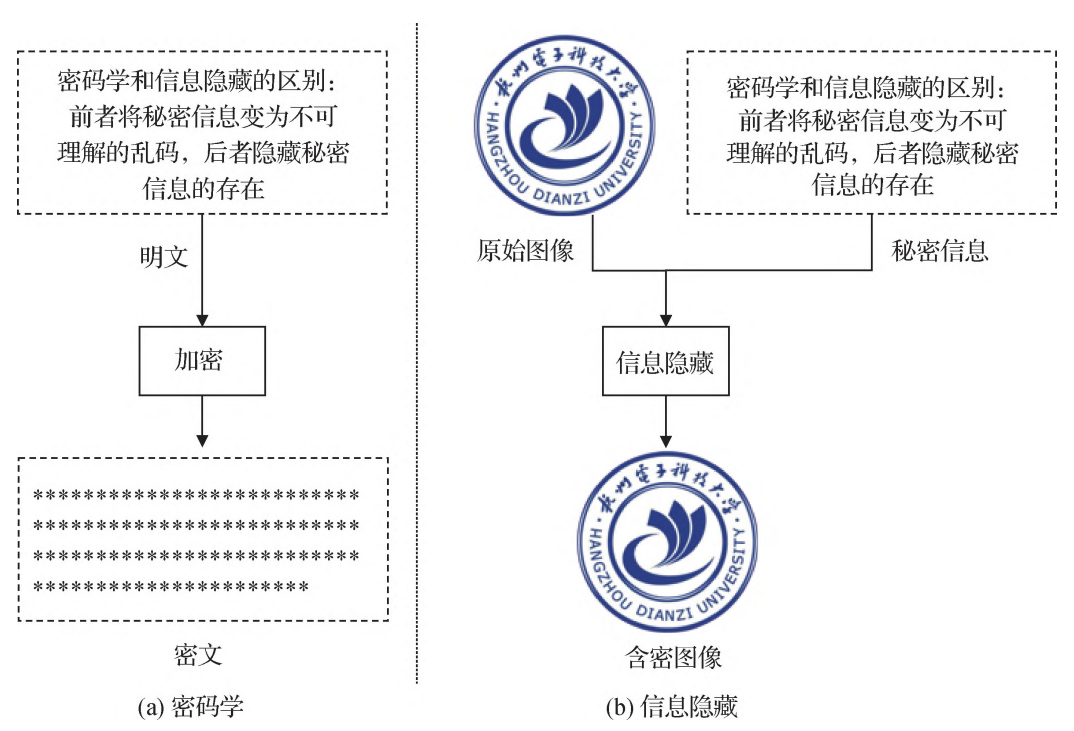
信息隐藏技术是一种通过将消息嵌入到载体中, 人们凭直观的视觉和听觉难以察觉其存在,以实现信息的保密传输和存储的方法。常见的信息隐藏技术包括数字水印、隐写术等。信息隐藏的目的不在于限制正常的信息存取和访问,而在于保证隐藏的信息不引起监控者的注意和重视,从而减少被攻击的可能性,在此基础上再使用密码术来加强隐藏信息的安全性,因此信息隐藏比信息加密更为安全。事实上,密码术(隐藏内容)和隐写术(隐藏行为)不是互相矛盾、互相竞争的技术,而是相互补充的技术,他们的区别在于应用的场合不同,对算法的要求不同,但可能在实际应用中需要互相配合。
AI security

Abstract
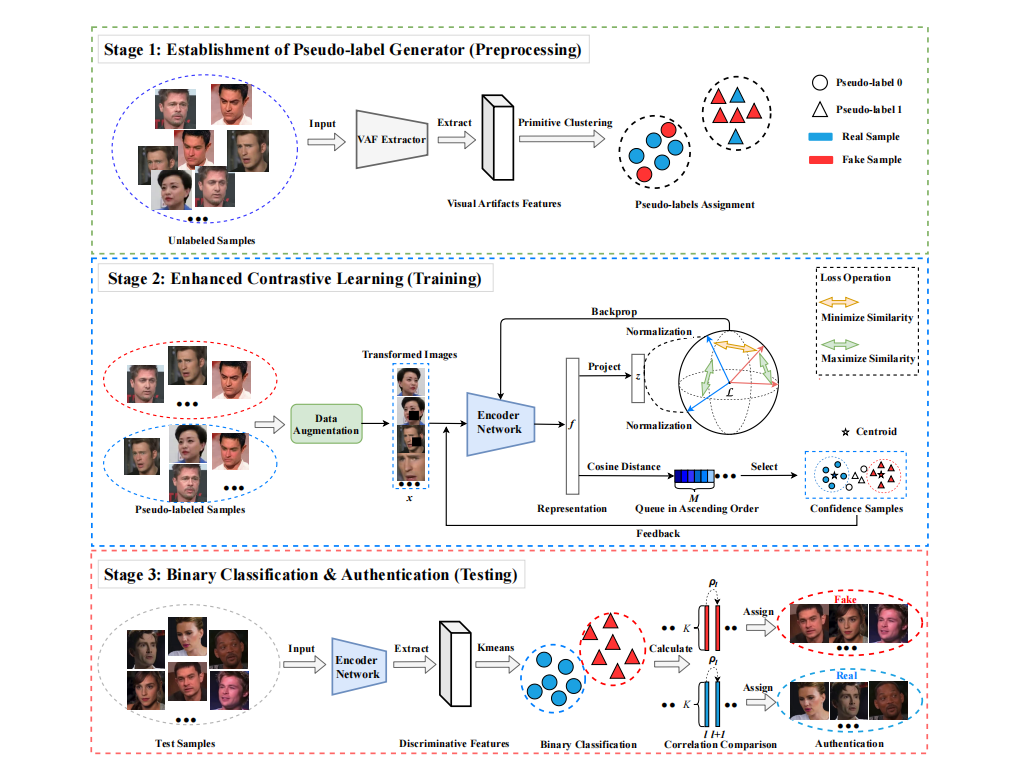
如今,深度伪造视频在互联网上广泛传播,严重损害了公众的信任和社会安全。尽管最近出现了越来越多可靠的检测器来抵御新型篡改技术,但仍然存在一些具有挑战性的问题需要解决,例如大多数有监督机制框架下的深度伪造视频检测器需要大量具有准确标签的样本进行训练。当具有真实标签的训练样本数量不足或训练数据被攻击者恶意投毒时,有监督分类器的检测结果可能不可靠。为了解决这一难题,本文设计了一个完全无监督的深度伪造检测器。要强调的是,在整个训练和测试过程中,我们不知道样本真实标签的任何信息。首先,本文创新性地设计了一个伪标签生成器,基于传统手工提取的特征区分两种类型的训练样本并生成标签。接着,将带有伪标签的训练样本输入到本文提出的增强对比学习器中,在对比损失的指导下,进一步提取判别特征并迭代优化。最后,依据帧间相关性完成真假视频的分类。大量的实验结果证实了本文提出的无监督深度伪造视频检测器在FF++、Celeb-DF、DFD、DFDC和UADFV等基准数据集上的有效性。此外,本文提出的检测器的性能优于当前的无监督方法,并与基准的有监督方法相当。更重要的是,当面对数据投毒攻击和训练数据不足的问题时,本文提出的无监督深度伪造检测器展现出优异的性能。
AI security

Abstract
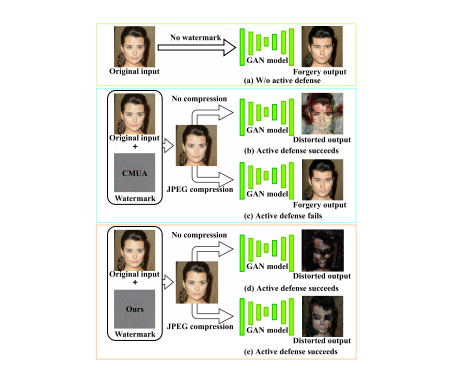
生成对抗网络(GAN)推动了面部篡改攻击的激增,这严重威胁了个人的隐私及声誉。其中一种应对措施是对抗性水印,它在GAN进行合成攻击之前被嵌入到受保护的图像中,导致恶意攻击者获得失真的合成内容。然而,在实际应用中,JPEG压缩通常会导致对抗性水印的性能显著下降。为了解决这一具有挑战性的问题,本文提出了一种新的鲁棒对抗性水印,即使受到JPEG压缩的影响,也能有效地抵御GAN的合成攻击。大量的实验证明了我们提出的方法在基准数据集上的优越性。更重要的是,所提出的对抗性水印的鲁棒性在模拟信道传输和真实社交网络平台上进行了全面的评估,其有效性进一步得到验证。
AI security


Abstract
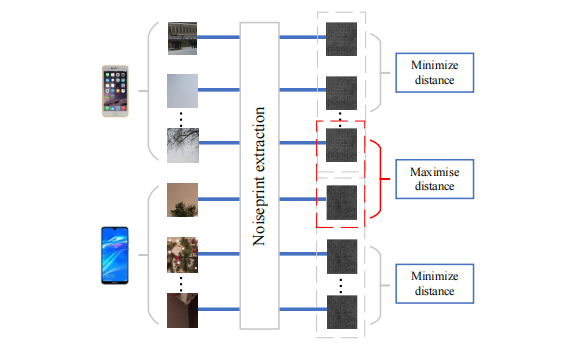
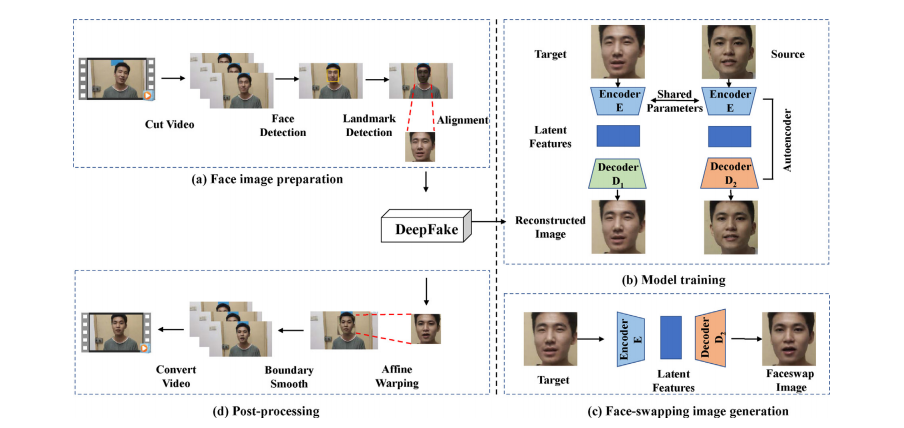
随着计算机硬件设备和深度学习技术的不断发展,人们通过利用当前新兴的多媒体篡改工具,可以轻松地在视频中实现人脸交换,如目前最流行的深度伪造技术。这引发了一系列新的安全威胁。尽管许多取证研究已关注这一新型篡改问题,并在检测准确度方面取得了显著进展。但大多数研究仍然基于有监督学习方法,需要大量有标记样本来训练模型。本文首次提出了一种用于识别深度伪造视频的新型无监督检测方法。我们方法的核心机理在于:真实视频中的人脸区域是由摄像机捕捉得到的,而深度伪造视频中的对应区域通常是由计算机生成的,这两者的来源完全不同。具体而言,我们的方法包括基于PRNU及noiseprint特征的两个聚类阶段。首先,提取每个视频帧的PRNU,用于对原始尺寸的源视频进行聚类(无论其真实性)。其次,我们从视频的人脸区域提取noiseprint,用于识别每个聚类中的深度伪造样本(再次进行聚类以进行二值分类)。实验证明,我们提出的无监督方法在自建数据集和作为基准的FF++数据上表现出色。更为重要的是,其性能不逊于基于有监督学习的最新检测方法。
AI security


Abstract
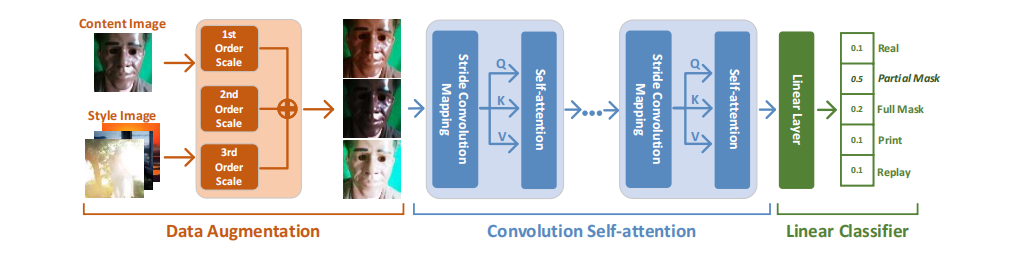
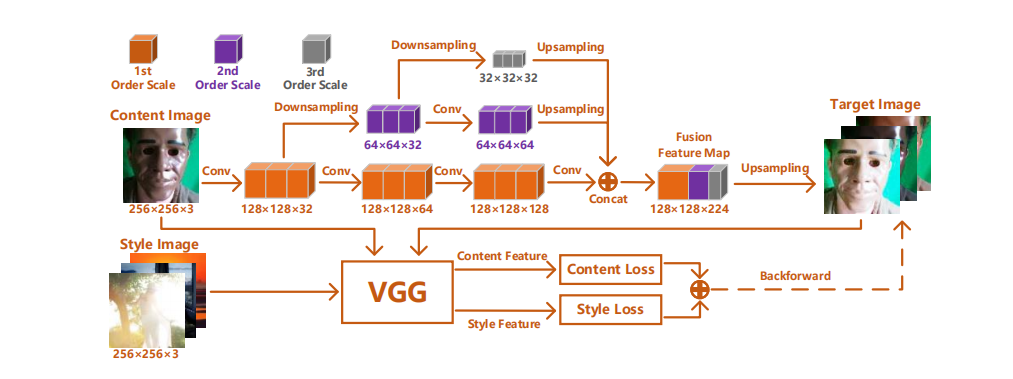
随着人脸识别技术的不断发展,人脸反欺骗作为人脸识别系统中至关重要的安全模块愈发凸显其重要性。然而,人脸反欺骗仍然是一项具有挑战性的任务,尤其是在同时面对各种攻击的场景下。此外,目前大多数检测器主要专注于二分类任务,往往无法完成细粒度多分类任务,包括重放攻击、打印攻击、部分遮罩攻击和完全遮罩攻击等。为了填补这一空缺,本文设计并提出一种细粒度的检测网络,用于对各种人脸欺骗攻击方式进行分类。首先,我们建立一个基于Transformer的特征提取网络,采用卷积映射操作替代传统的线性映射。具体而言,我们采用自注意模块来提取全局特征,并运用卷积映射来保持模型提取局部特征的能力。最后,我们引入了简单而高效的线性分类器来进行细粒度分类。此外,借助基于 VGG 的风格迁移网络,我们提出了一个精心设计的数据增强模块,以解决训练样本不足的问题。在大规模的实验中,与基准检测器相比,我们提出的高效细粒度分类器在多分类任务方面表现优异。
AI security

Abstract
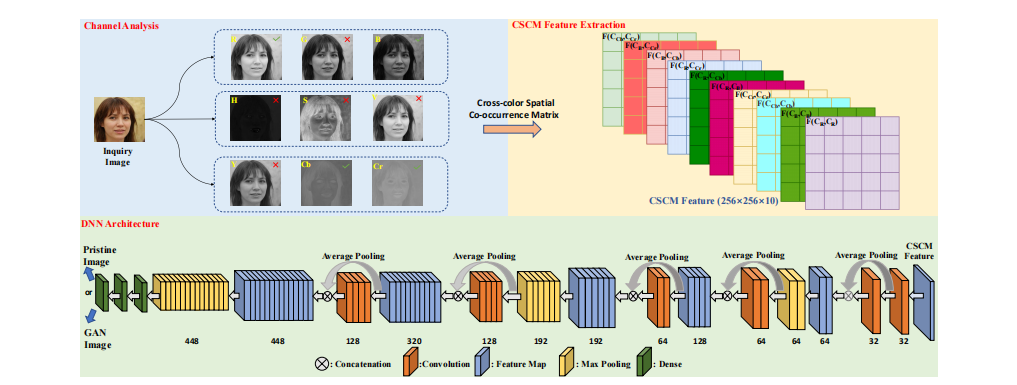
最近,生成对抗网络(GAN)生成的图像在社交网络中广泛传播,给媒体取证领域带来了新的挑战。虽然一些可靠的取证工具推动了检测GAN生成图像的研究,但在面对恶意的后处理攻击时,特别是在实际的社交网络场景中,检测的准确性无法保证。因此,在这一背景下,我们提出了一种新颖的深度神经网络,利用手工提取的特征来解决这个问题。具体来说,我们依靠跨颜色空间的共生矩阵(CSCM),经过仔细分析和选择最有效的颜色通道后,提取出具有区分性的特征。然后,将融合后的特征输入深度神经网络,训练出一个高效的取证检测器。大量实验结果验证了在大多数检测场景下,尤其是在面对后处理攻击时,我们提出的检测器性能优于SOTA方法。此外,我们评估了所提出的检测器在现实社交网络平台的有效性,以及它在三种不同场景下的泛化能力。
AI security

Abstract
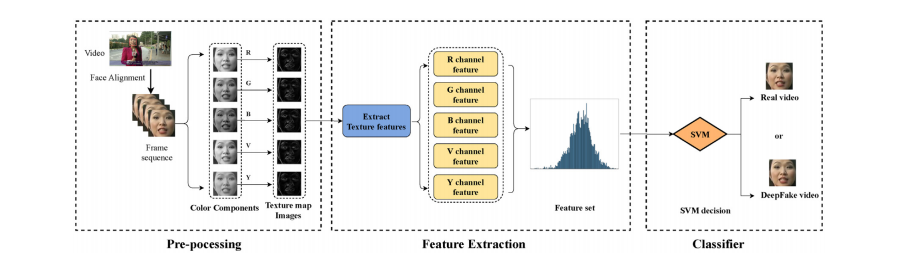
随着深度学习的发展,诸如深度伪造等人工智能合成技术在互联网上广泛传播。尽管许多先进的检测方法已经展现出良好的检测性能,但大多数基于数据驱动的神经网络模型在特征提取和分析过程中缺乏可解释性。因此,本文提出了一种基于多色彩通道中人脸纹理差异的可解释深度伪造视频检测方法。我们观察到深度伪造视频中的人脸区域看起来要比真实视频中的人脸区域更加平滑。首先,我们分析了每个色彩通道中真假视频帧之间的统计特征差异。其次,我们提出使用共生矩阵构建低维特征集,以区分真假视频。同时,我们在基准数据集上对本文方法的视频片段级和视频帧级检测性能进行了评估,在FaceForensics++数据集上AUC达到了0.996,在Celeb-DF数据集上AUC达到了0.718。本文提出的方法的检测性能明显优于传统的基于机器学习的方法,并且与当前基于深度学习的方法相当。更为重要的是,本文提出的方法在应对人脸压缩攻击时表现出鲁棒性,且比现有的基于深度学习的方法更为高效。
Source attribution

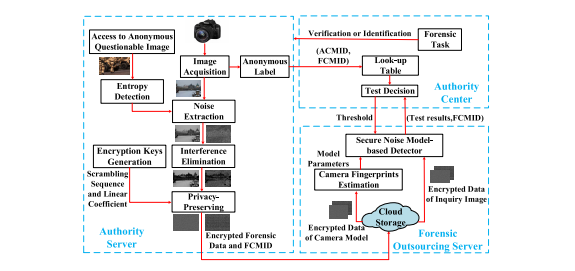

Abstract
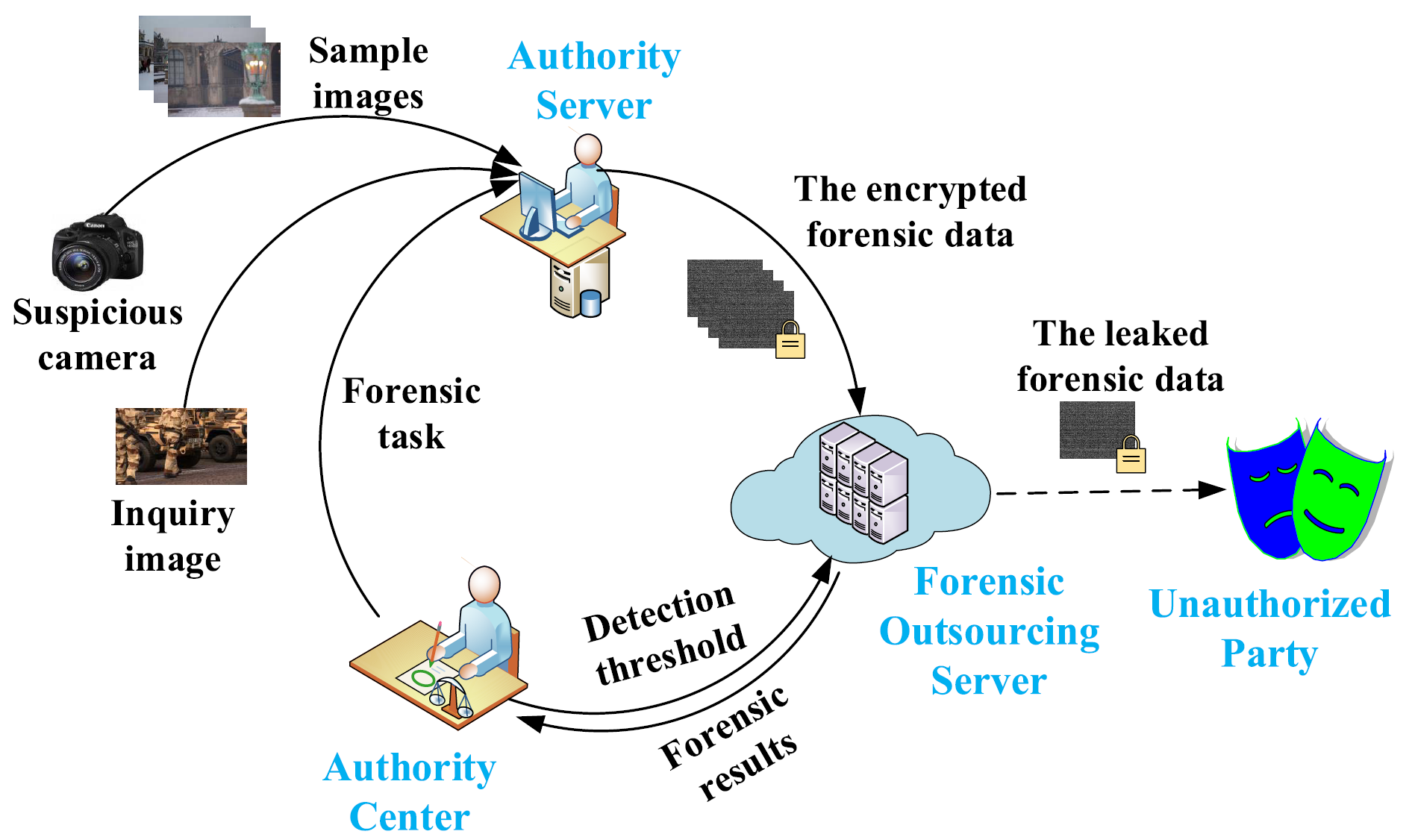
为了解决查询图像的相机源识别问题,已经提出了许多取证方法。然而,对查询图像进行取证需要耗费大量的计算开销,同时存在可能的隐私泄露威胁,使得许多现有的取证方法应用受限。只有少数研究工作提出了安全的取证方法来解决上述问题,而这些方法,并未对统计性能进行详细分析。本文提出了一种高效的隐私保护取证方法,具备分析统计性能的能力,可有效且安全地解决相机源识别问题。为了保护查询图像的隐私,我们提出了一种混合隐私保护方案,包括两个操作:位置混淆加密用于保护图像内容的隐私,以及噪声线性映射处理用于保护查询图像的相机源身份的隐私。在采用隐私保护方案的加密域,我们首先提出了一种新的统计噪声模型,该模型可以准确地表征加密的JPEG查询图像。同时,我们设计了一种基于噪声模型的检测器,用于识别不同的相机型号。实验结果验证了我们提出的方法在隐私保护和取证有效性两个方面的可行性。需要特别强调的是,我们的方法在样本图像不足时,可以高效且准确地估计相机指纹。在仅有两张图像提取指纹的情况下,我们的方法优于当前的基线方法。
Source attribution

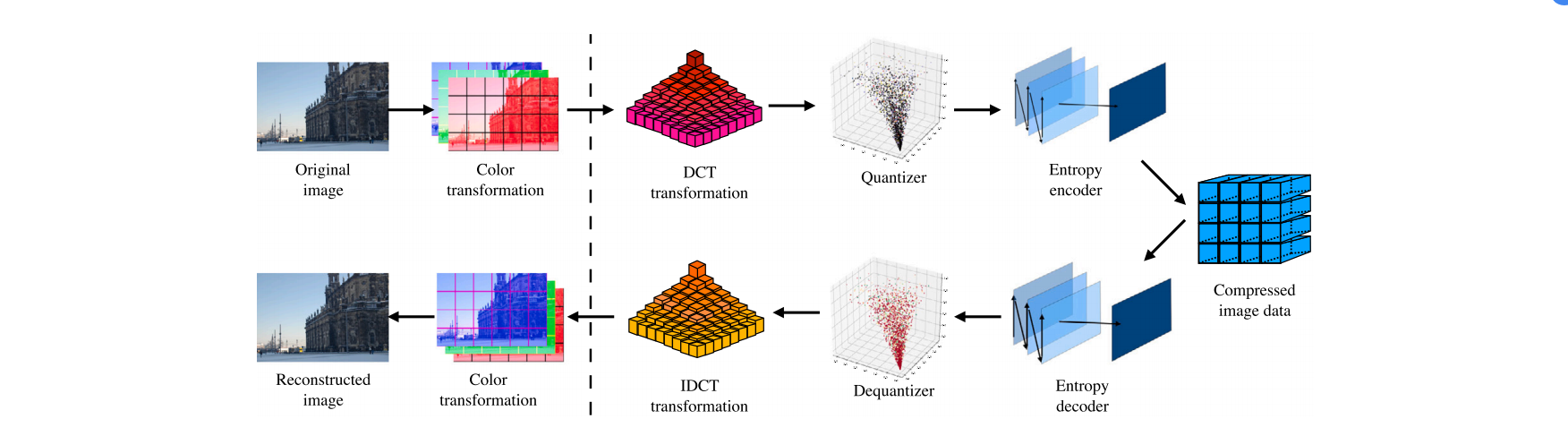
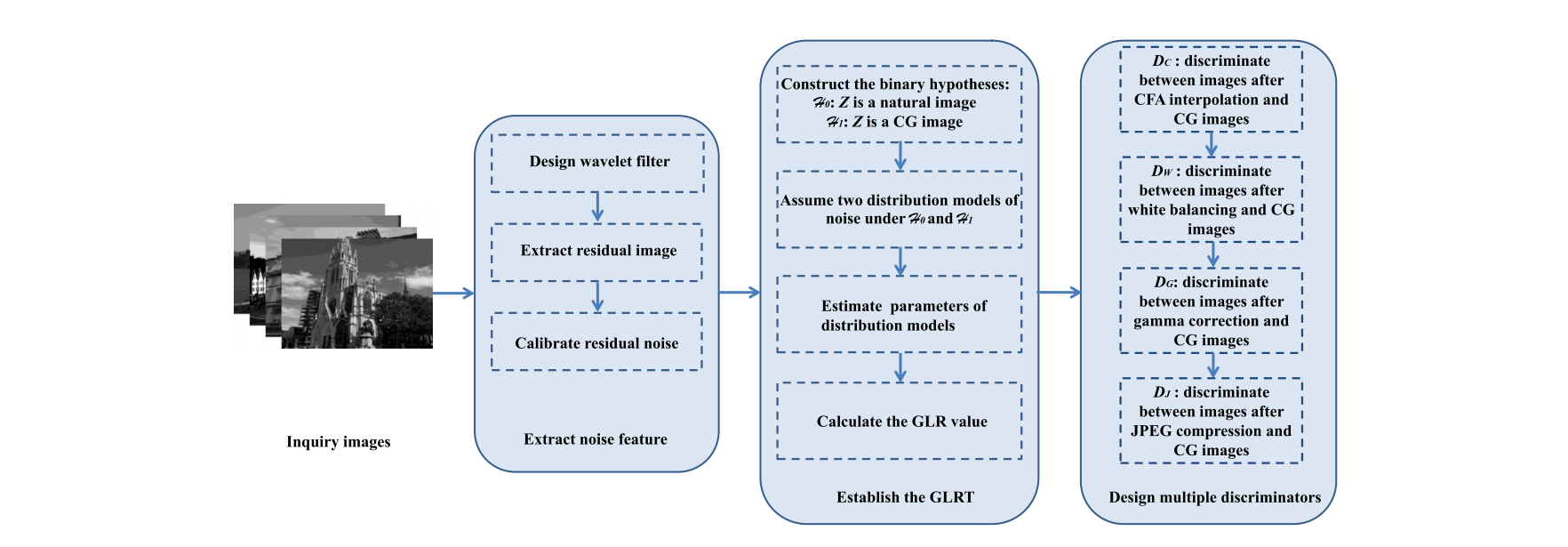
Abstract
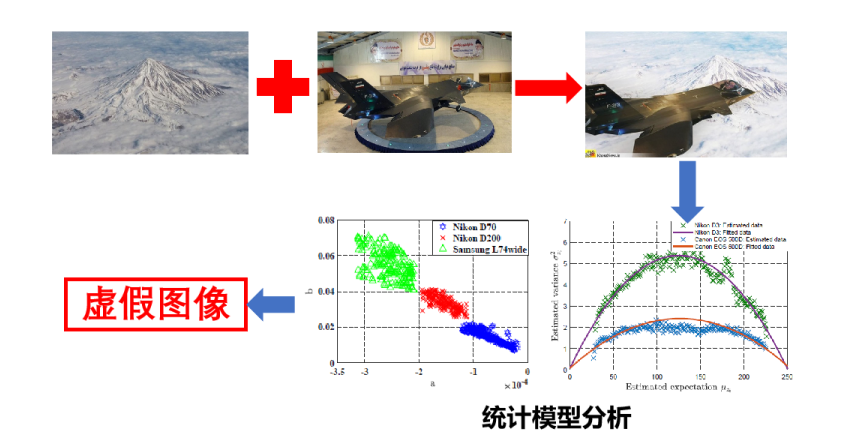
计算机生成(CG)图像在互联网上逐渐泛滥,使得难以将其与真实成像设备捕获的自然图像(NIs)区分。尽管一些鉴别器可以处理JPEG格式的NIs,但面对未经压缩的NIs和CG图像之间的分类问题时,效果仍然未知。因此,本文旨在建立多个鉴别器,对NIs和CG图像进行分类。我们首先阐述了图像主要的成像过程及其固有属性,这些属性表征了可用于分类的鉴别特征。接着,我们提取了残差噪声,其统计分布有助于我们建立多个鉴别器,包括在假设检验理论框架下的广义似然比检验。大量的实验结果证明了我们提出的多个鉴别器在性能上优于许多基线方法。此外,考虑到可能存在的后处理攻击,我们也验证了鉴别器的鲁棒性。
Source attribution

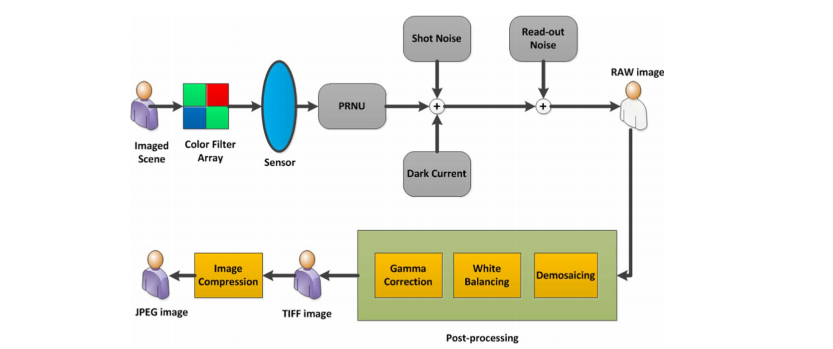
Abstract
本文旨在研究JPEG格式自然图像的源相机设备识别问题。我们提出了一种改进的信号相关噪声模型,用于描述JPEG图像中像素的统计分布。该噪声模型依赖于异质的噪声参数,这些参数将像素噪声的方差与期望相关联作为唯一指纹特征。同时,我们通过表征线性关系来获取像素的非线性响应,使用这些异质的噪声参数来识别来源相机设备,识别问题被归纳为假设检验理论的统一框架内。在理想情况下,即所有模型参数都是完全已知,我们提出将似然比检验(LRT)作为检测能力的上界。在实际场景中,当干扰参数未知时,我们建立了基于这些参数估计的两个广义LRT。通过对模拟数据和真实自然图像数据的分析,实验结果展现了我们提出方法的有效性。尽管这些结果首次证明了该方法的概念,但仍需要对其进行扩展,以便与已经经过长期验证的基于PRNU的基线方法进行相关比较。
Tampering detection



Abstract
鉴别重采样图像的取证问题已经开展多年。然而,目前很少有研究提出基于统计模型的检测方法,导致不能充分分析重采样检测器的统计性能。为了填补这一空缺,我们利用一种参数模型揭示了重采样伪造的痕迹,这种痕迹以残差噪声分布的形式描述。具体地,我们提出了一个统计模型,用于描述重采样图像中的残差噪声,检测问题因此被纳入假设检验理论的框架中。在设计纹理权重图的同时,考虑图像内容,建立了两种类型的统计检测器:在理想情况下,即所有分布参数都是已知的情况下,我们提出了似然比校检测器(Likelihood Ratio Test, LRT),并在理论上对其性能进行了建模,通过利用LRT的统计性能,我们成功获得了检测性能的上界;在实际应用中,即分布参数未知的情况下,我们建立了基于参数估计的广义LRT,其中包含三种不同映射。在模拟数据和真实自然图像上的数值结果证明了我们提出方法的相关性。
Tampering detection


Abstract
随着图像重着色技术的发展,经重着色的图像(Recolored Image, RIs)变得越来越真实,很难在视觉上将其与自然图像(Natural Images, NIs)区分开来。最近,研究者们提出了一系列针对RIs的检测方法。然而,当前的检测方法仍然存在一些局限性,例如泛化性能差、需要大规模的训练样本、训练特征维度高以及计算成本高等。为了解决这些问题,本文提出了一种基于横向色差(Lateral Chromatic Aberration, LCA)不一致性及其统计差异的新方法。一般来说,与NIs相比,RIs的LCA特征较少,这启发了我们设计用于区分两种类型图像的分类器。特别地,我们提出采用低维特征输入至SVM的机制,使用基准的ImageNet和Oxford数据集来验证所提方法的有效性,其中我们提出的方法的性能与当前最新研究媲美。
Tampering detection



Abstract
为了解决图像拼接篡改的检测问题,学者已经提出了许多取证工具。大多数现有工具在基于大规模训练数据的有监督场景中表现出色,但它们的统计性能无法被充分分析和建模。因此,我们提出了基于统计模型的图像取证检测器,即一种无需训练的具有分析统计性能的取证检测器,可用于图像拼接伪造检测。该检测器的设计基于JPEG图像的简化噪声模型,该模型假设像素方差是像素期望的二次函数。所提出的简化噪声模型由两个参数表征,这两个参数可用作图像伪造检测的相机指纹。通过采用假设检验理论的框架,设计了一种无需训练的广义似然比检验(Generalized Likelihood Ratio Test, GLRT),该检验确保在指定的虚警率下实现高检测性能。此外,检测阈值可以与图像内容无关的方式配置。数值结果验证了简化噪声模型的准确性以及所提出的检测器的有效性。
Data hiding

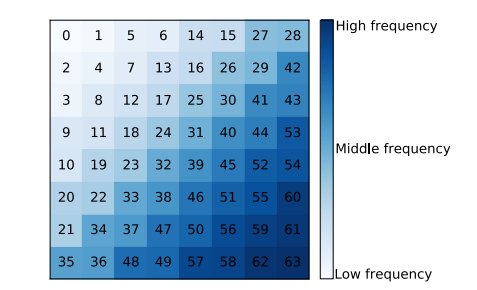
Abstract
在当前的隐写分析领域,广泛采用的有监督机制需要在训练阶段依靠大量样本。然而,鲜有研究关注于设计高效且无需训练的无监督自适应检测器。为了填补这一研究空白,本文提出了一种基于统计模型的自适应检测器,用于检测JPEG隐写算法。首先,本文借助假设检验理论并结合量化DCT系数的分布,建立了基于统计模型检测器的整体框架。其次,基于该框架,本文分析了统计模型的选择、参数估计和有效载荷对检测器性能的影响。接着,为了提高检测的可靠性,本文基于DCT通道分配权重策略,创新性地提出了基于统计模型的自适应检测器,用于检测JPEG隐写算法,包括通道选择和非通道选择算法。大量实验证明了本文提出的方法的有效性。此外,实验结果表明,当检测两种小负载隐写算法的JPEG图像时,本文提出的自适应检测器的AUC分别为0.9567和0.9895,均优于非自适应检测器。
Data hiding


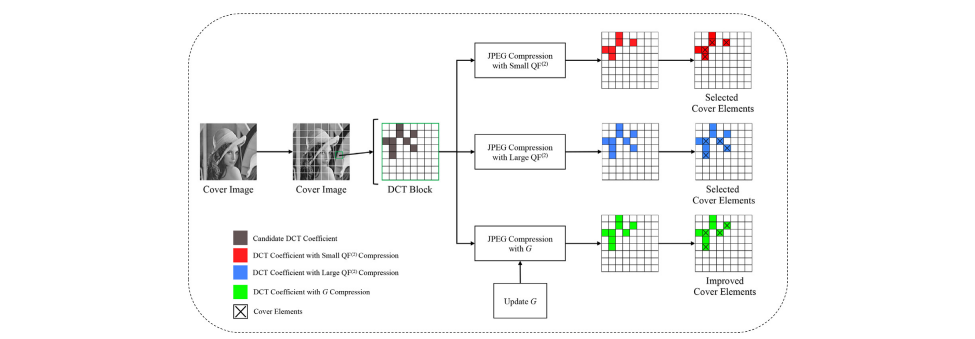
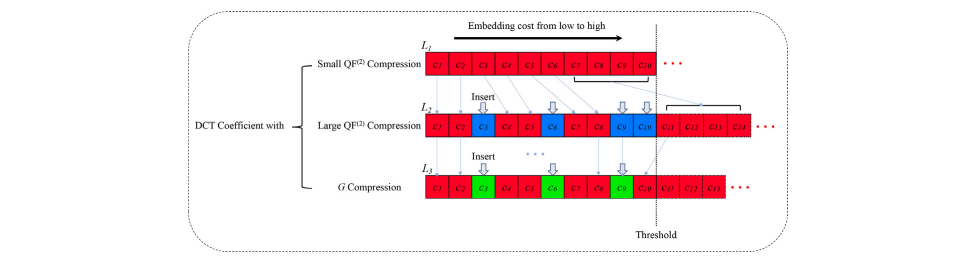
Abstract
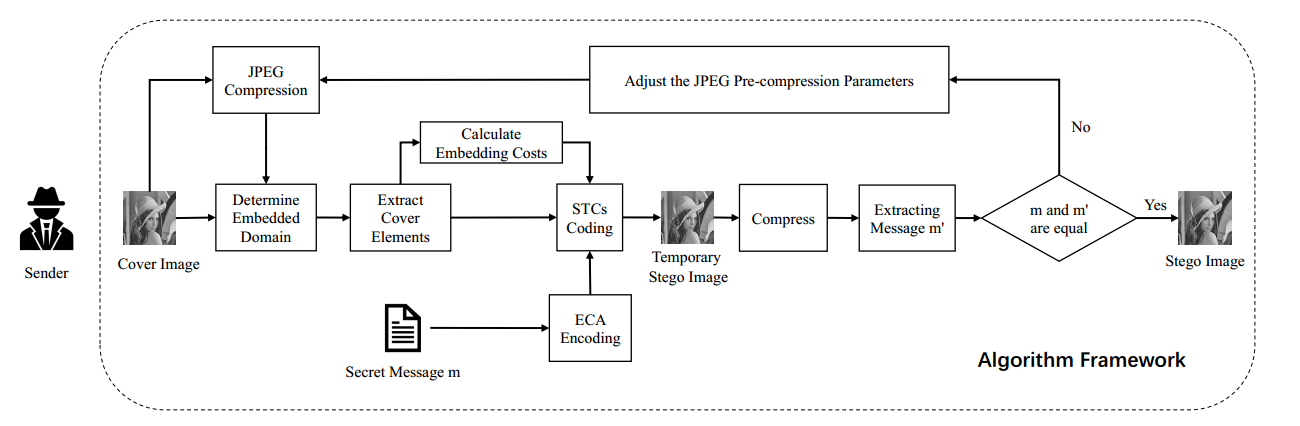
通过最小化嵌入代价,当前自适应隐写术的不可检测性取得了前所未有的成功。然而,由于图像在社交网络平台传输中经过JPEG压缩操作,导致无法正确提取其中隐藏的秘密比特信息,这极大地限制了隐写术在现实世界中的广泛应用。本文通过改善载体元素的选择,提出了一种增强的鲁棒隐写算法,旨在抵抗JPEG压缩的影响。首先,由于JPEG压缩前后DCT系数的符号不易改变,本文基于DCT系数的符号设计载体元素。其次,通过对后处理操作的分析改善了载体元素的选择。再次,计算每个候选DCT系数的嵌入代价。最后,使用纠错算法和STC最小化嵌入引起的失真,生成抗压缩的隐写图像。实验结果验证了本文提出的隐写算法的鲁棒性优于现有隐写算法。同时,我们也在社交网络平台上验证了该算法的有效性。
Data hiding

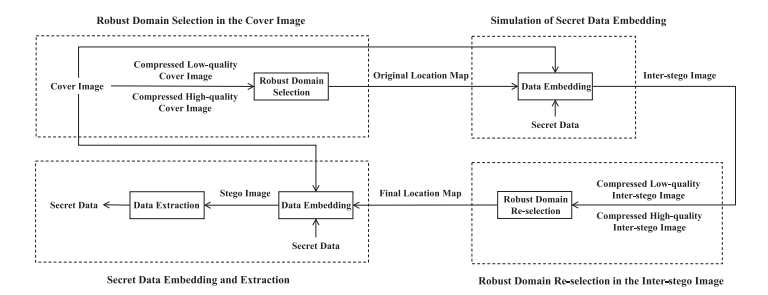
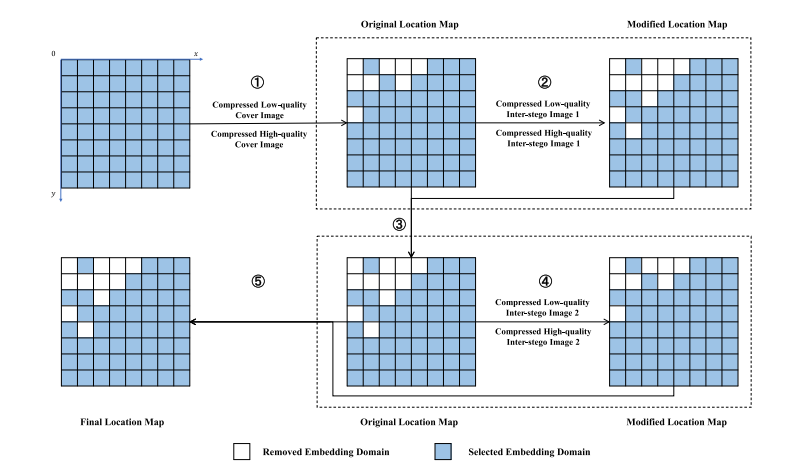
Abstract
为了在现实世界中实现隐蔽通信,鲁棒隐写术引起了广泛关注。本文创新性地提出了一种基于DCT符号进行鲁棒域选择的鲁棒隐写术,称为SSR(Sign Steganography Revisited)。现有隐写术通过选择鲁棒的载体元素来保证算法的鲁棒性。然而,数据嵌入可能导致选择的元素失效。因此,SSR选择压缩前后不变的隐写元素,同时,删除纠错编码以提高不可检测性。具体而言,用88块表示所有的嵌入域,并进一步选择隐写元素不变的鲁棒嵌入域。这有效地减少了所选嵌入域的共享位置信息。此外,本文从理论上证明了在特定范围进行压缩后,能够实现无差错提取。本文还通过校正失真函数,提高了SSR的不可检测性。实验结果表明了本文提出的SSR在有损信道中的有效性,也在社交网络平台上验证了SSR的实用性。
Data hiding

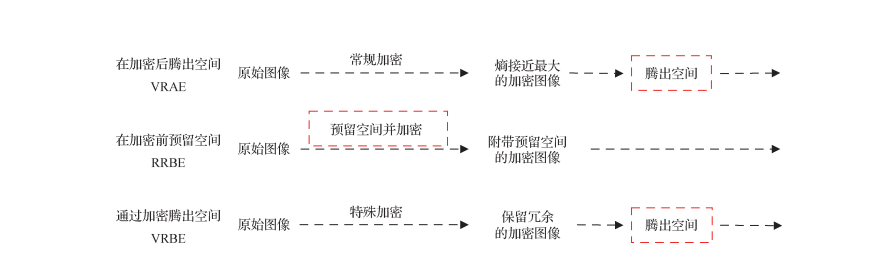

Abstract
可逆信息隐藏是信息隐藏技术的重要分支,它不仅能从含密载体中提取秘密信息,还能无损地还原原始载体。以图像空域为载体的可逆信息隐藏研究根据图像是否被加密可分为明文域和密文域。早期,该领域研究基本 在明文域开展,在保证可逆嵌入的前提下,着重提高嵌入容量与减少嵌入失真。随着人们日益重视隐私保护和数据安全,密文域的信号处理引起广泛关注。密文域可逆信息隐藏结合加密技术和可逆信息隐藏技术,从而达到载体内容保护和秘密信息传递的双重目的。本文梳理现有的相关文献,分别对明文域和密文域的研究进行归纳与分析,按照时间先后顺序帮助理清各类方法的发展脉络及其关联。首先,概括明文域的经典方法,包括差值扩展、直方图平移、预测误差扩展和多直方图修改 4 种方法及其改进版本。其次,阐述密文域中基于加密后腾出空间、加密前预留空间和通过加密腾出空间 3 类方法的研究进展。再次,总结指出明文域的研究趋向于减少嵌入失真,而密文域的研究趋向于提高嵌入容量,其在鲁棒性及安全性方面的进展则相对缓慢。最后,结合当前研究面临的实际问题,如载体多元化、有损信道传输和安全性等,进一步展望未来的研究趋势。总之,可逆信息隐藏研究的有效性与实用性仍有待提高,面向不同应用需求时,亟需学者提出新的理论支撑与评价体系。